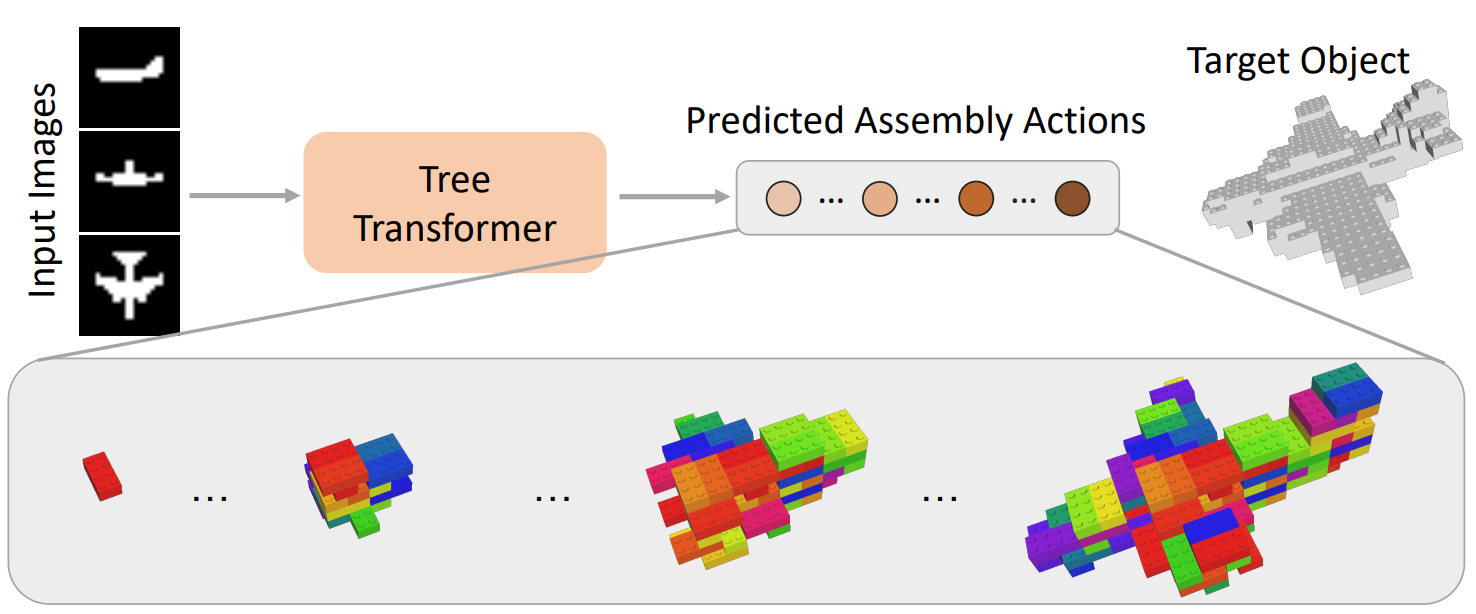
Inferring step-wise actions to assemble 3D objects with primitive bricks from images is a challenging task due to complex constraints and the vast number of possible combinations. Recent studies have demonstrated promising results on sequential LEGO brick assembly through the utilization of LEGO-Graph modeling to predict sequential actions. However, existing approaches are class-specific and require significant computational and 3D annotation resources. In this work, we first propose a computationally efficient breadth-first search (BFS) LEGO-Tree structure to model the sequential assembly actions by considering connections between consecutive layers. Based on the LEGO-Tree structure, we then design a class-agnostic tree-transformer framework to predict the sequential assembly actions from the input multi-view images. A major challenge of the sequential brick assembly task is that the step-wise action labels are costly and tedious to obtain in practice. We mitigate this problem by leveraging synthetic-to-real transfer learning. Specifically, our model is first pre-trained on synthetic data with full supervision from the available action labels. We then circumvent the requirement for action labels in the real data by proposing an action-to-silhouette projection that replaces action labels with input image silhouettes for self-supervision. Without any annotation on the real data, our model outperforms existing methods with 3D supervision by 7.8% and 11.3% in mIoU on the MNIST and ModelNet Construction datasets, respectively.
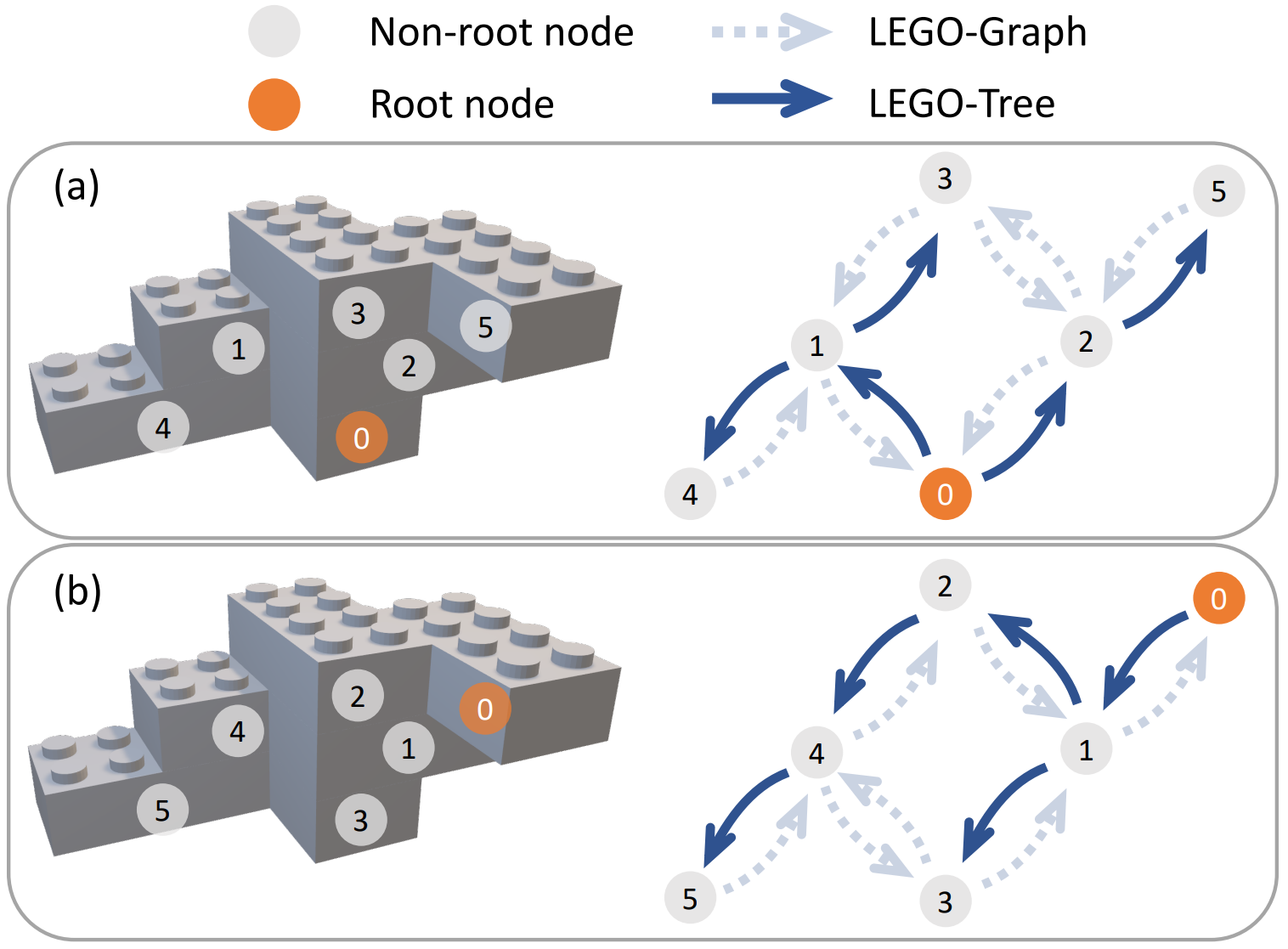
Illustration of the LEGO-Tree model and action reordering data augmentation. Node number represents the index of action in the sequence and the index of brick in the tree. (a) shows a BFS LEGO-Tree (solid line) generated from a LEGO-Graph (dotted line). (b) is an action-reordering augmented sample of (a).
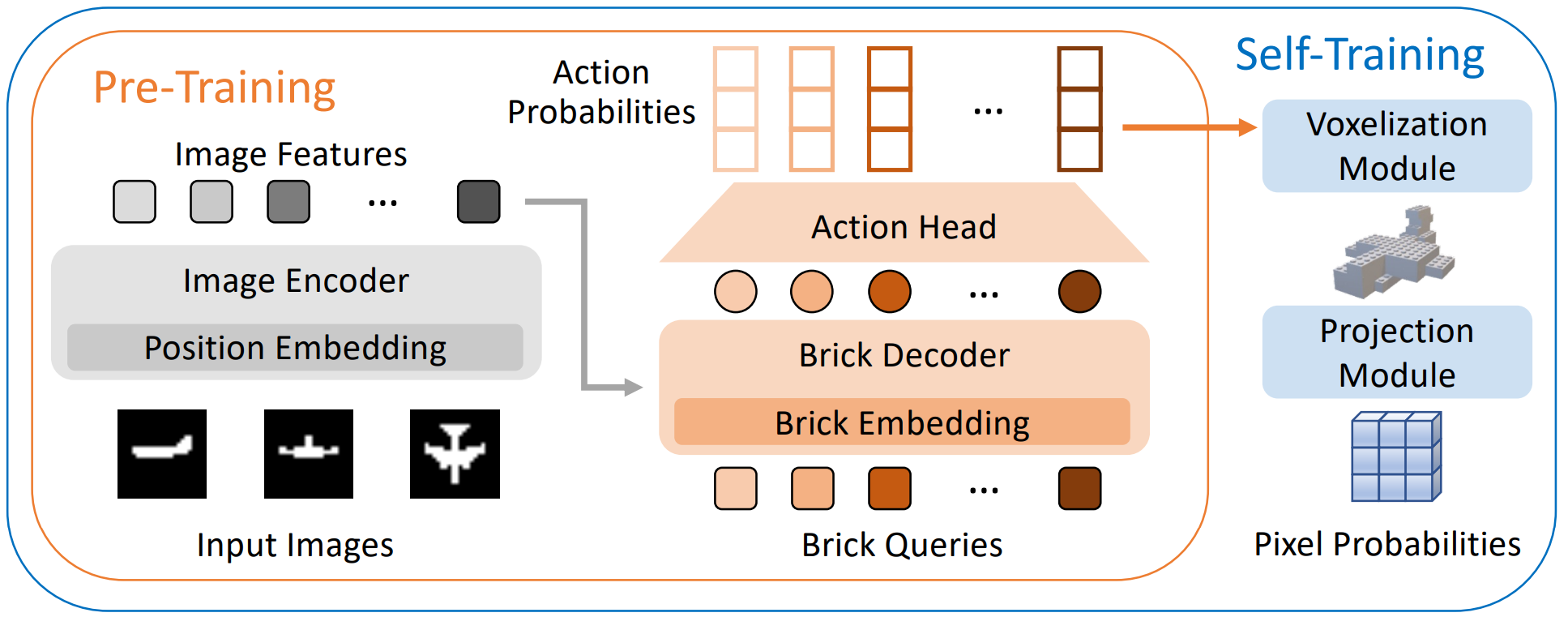
Overview of our two-stage framework that consists of a pre-training stage and a self-training stage. In the pre-training stage, we use an image encoder to extract the image features, which are fed into a brick decoder to estimate the action sequence. The estimated actions are supervised with ground truth action labels. In the self-training stage, we use voxelization and projection modules to transfer action probabilities into pixel probabilities such that the model can be self-supervised with the input images.

An example to illustrate the silhouette self-training with the input images $I$. Given the action probabilities $P^A=[p_0,p_1,p_2]$, a 4-step approach is used to compute the pixel probabilities $P^I=[p^I_0,p^I_1,p^I_2]$.
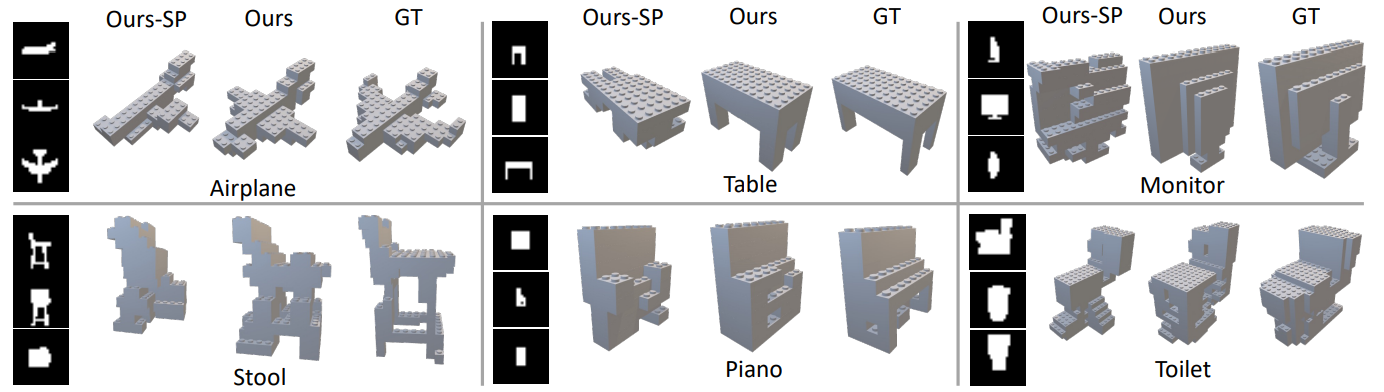
Visualization of the assembled objects in the ModelNet40-C. 'Ours-SP' is the result of the model only with pre-training.

Visual comparison of baselines, brick number, brick size.
@article{Guo2024TreeSBA,
author = {Guo, Mengqi and Li, Chen and Zhao, Yuyang and Lee, Gim Hee},
title = {TreeSBA: Tree-Transformer for Self-Supervised Sequential Brick Assembly},
journal = {European Conference on Computer Vision (ECCV)},
year = {2024},
}